Introducing Qwen-VL
Along with the rapid development of our large language model Qwen, we leveraged Qwen’s capabilities and unified multimodal pretraining to address the limitations of multimodal models in generalization, and we opensourced multimodal model Qwen-VL in Sep. 2023. Recently, the Qwen-VL series has undergo
Along with the rapid development of our large language model Qwen, we leveraged Qwen’s capabilities and unified multimodal pretraining to address the limitations of multimodal models in generalization, and we opensourced multimodal model Qwen-VL in Sep. 2023. Recently, the Qwen-VL series has undergone a significant upgrade with the launch of two enhanced versions, Qwen-VL-Plus and Qwen-VL-Max. The key technical advancements in these versions include:
- Substantially boost in image-related reasoning capabilities;
- Considerable enhancement in recognizing, extracting, and analyzing details within images and texts contained therein;
- Support for high-definition images with resolutions above one million pixels and images of various aspect ratios.
| Model Name | Model Description |
| qwen-vl-plus | Qwen's Enhanced Large Visual Language Model. Significantly upgraded for detailed recognition capabilities and text recognition abilities, supporting ultra-high pixel resolutions up to millions of pixels and arbitrary aspect ratios for image input. It delivers significant performance across a broad range of visual tasks. |
| qwen-vl-max | Qwen's Most Capable Large Visual Language Model. Compared to the enhanced version, further improvements have been made to visual reasoning and instruction-following capabilities, offering a higher level of visual perception and cognitive understanding. It delivers optimal performance on an even broader range of complex tasks. |
{/*  */}
*/}
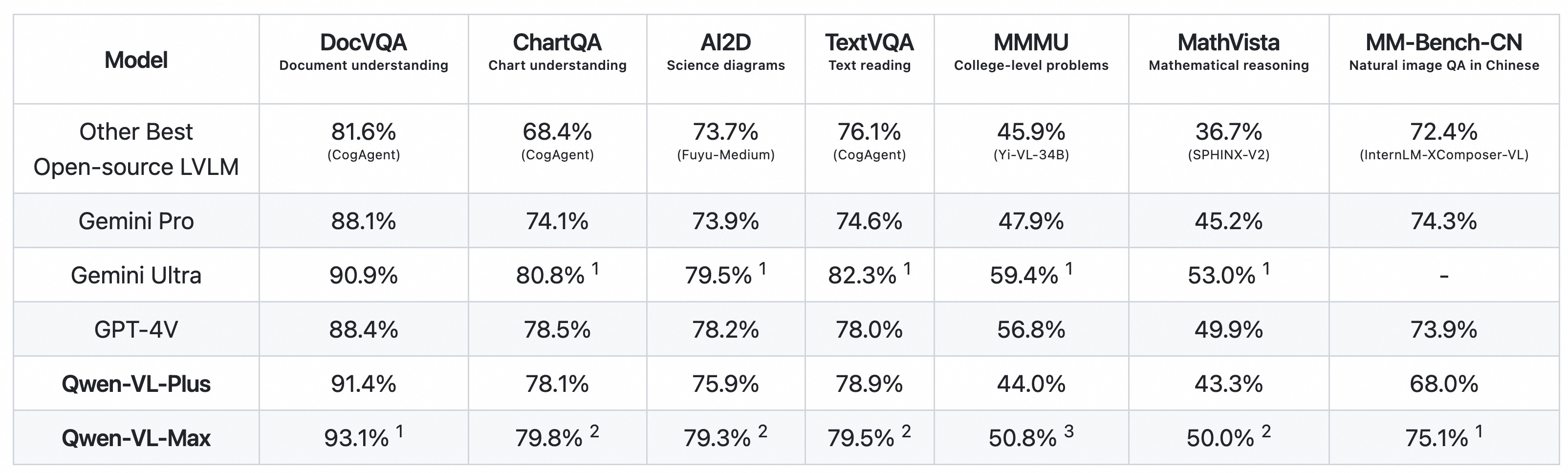
Compared to the open-source version of Qwen-VL, these two models perform on par with Gemini Ultra and GPT-4V in multiple text-image multimodal tasks, significantly surpassing the previous best results from open-source models.
Notably, Qwen-VL-Max outperforms both GPT-4V from OpenAI and Gemini from Google in tasks on Chinese question answering and Chinese text comprehension. This breakthrough underscores the model's advanced capabilities and its potential to set new standards in the field of multimodal AI research and application.
| Model | DocVQA Document understanding |
ChartQA Chart understanding |
AI2D Science diagrams |
TextVQA Text reading |
MMMU College-level problems |
MathVista Mathematical reasoning |
MM-Bench-CN Natural image QA in Chinese |
|---|---|---|---|---|---|---|---|
| Other Best Open-source LVLM |
81.6% (CogAgent) |
68.4% (CogAgent) |
73.7% (Fuyu-Medium) |
76.1% (CogAgent) |
45.9% (Yi-VL-34B) |
36.7% (SPHINX-V2) |
72.4% (InternLM-XComposer-VL) |
| Gemini Pro | 88.1% | 74.1% | 73.9% | 74.6% | 47.9% | 45.2% | 74.3% |
| Gemini Ultra | 90.9% | 80.8% 1 | 79.5% 1 | 82.3% 1 | 59.4% 1 | 53.0% 1 | - |
| GPT-4V | 88.4% | 78.5% | 78.2% | 78.0% | 56.8% | 49.9% | 73.9% |
| Qwen-VL-Plus | 91.4% | 78.1% | 75.9% | 78.9% | 45.2% | 43.3% | 68.0% |
| Qwen-VL-Max | 93.1% 1 | 79.8% 2 | 79.3% 2 | 79.5% 2 | 51.4% 3 | 50.0% 2 | 75.1% 1 |
{/*  /}
{/
/}
{/  */}
*/}
New versions of the Qwen-VL-Plus and Qwen-VL-Max models not only exhibit exceptional benchmark performance but also demonstrate a marked improvement in problem-solving capabilities within real-world scenarios. These advanced models effortlessly engage in dialogue, identify celebrities and landmarks, generate text, and notably, have significantly enhanced their abilities to describe and interpret visual content.
Here we present some practical examples:
1. Basic Recognition Capabilities
The latest Qwen-VL models are now more adept at accurately describing and identifying complex information within images, as well as providing detailed background and answering related questions. For instance, Qwen-VL can recognize not only common objects, but also celebrities and landmarks. Qwen-VL can write poetry in various languages inspired by visuals, and analyze everyday screenshots.
{/* Interactive example: 1_celeb.json /} {/ Interactive example: 1_2.json /} {/ Interactive example: 1_3.json /} {/ Interactive example: 1_4.json */}
2. Visual Agent Capability: The Essential Role of Localization
Beyond its fundamental capabilities in description and recognition, Qwen-VL also has impressive abilities to pinpoint and query specific elements. For instance, it can accurately highlight the black cars within an image. Moreover, Qwen-VL is also equipped to make judgments, deductions, and decisions based on the prevailing context of a scene.
{/* Interactive example: 2_visual_grounding.json /} {/ Interactive example: 2_grounded_caption.json /} {/ Interactive example: 2_driving.json */}
3. Visual Reasoning Capability: To Solve Real Problems
One of the most notable advancements in the latest Qwen-VL is its capacity for complex reasoning based on visual inputs. This enhanced visual reasoning capability goes well beyond mere content description, extending to the comprehension and interpretation of intricate representations such as flowcharts, diagrams, and other symbolic systems. In the realms of problem-solving and reasoning, Qwen-VL-Plus/Max excels not only in mathematical problem-solving and information organization but also in conducting more profound interpretations and analyses of charts and graphs.
{/* Interactive example: 3_1.json /} {/ Interactive example: 3_2.json /} {/ Interactive example: 3_3.json /} {/ Interactive example: 3_4.json /} {/ Interactive example: 3_5.json */}
4. Text Information Recognition & Processing
Text processing in images has also improved significantly, especially in terms of recognizing Chinese and English text. Qwen-VL-Plus/Max can now efficiently extract information from tables and documents and reformat this information to meet custom output requirements. In addition, it has an efficient mechanism for identifying and converting dense text, which is very effective in dealing with documents that contain a lot of information. It supports images with extreme aspect ratios, ensuring the flexibility to process diverse visual content.
{/* Interactive example: 3_6.json /} {/ Interactive example: 4_1.json /} {/ Interactive example: 4_2.json */}
How to Use
Now you can access Qwen-VL-Plus and Qwen-VL-Max through the Huggingface Spaces, the Qwen website, and Dashscope APIs.
- Try Qwen-VL-Plus (https://huggingface.co/spaces/Qwen/Qwen-VL-Plus) and Qwen-VL-Max (https://huggingface.co/spaces/Qwen/Qwen-VL-Max) in the Huggingface Spaces
- Log in to the QianWen web portal at https://tongyi.aliyun.com/qianwen, and switch to "Image Understanding" mode to harness the latest Qwen-VL-Max capabilities.

- Access the powerful APIs of Qwen-VL-Plus and Qwen-VL-Max through the Dashscope platform (https://help.aliyun.com/zh/dashscope/developer-reference/vl-plus-quick-start).

Summary
Qwen-VL-Plus and Qwen-VL-Max make significant strides in enhancing high-resolution recognition, text analysis, and image reasoning capabilities. These models now match the performance of GPT4-v and Gemini, outperforming all other open-source and proprietary models in many tasks, such as MMMU, CMMMU, and MathVista. They achieve world-class results in document analysis (DocVQA) and Chinese language-related image understanding (MM-Bench-CN).
Our objective is to continually tap into and elevate the potential of Qwen-VL, enabling it to make a difference across a broader range of applications. We can envision Qwen-VL as an assistant equipped with superhuman visual and linguistic comprehension skills that can provide robust support in everyday dialogues as well as complex scenarios like driving environments and programming contexts.
While there is still a long way to go, we are confident that Qwen-VL will evolve to perceive and understand the world akin to human cognition through continuous optimization and expansion!
- Our Official Website: https://tongyi.aliyun.com/qianwen
- Github: https://github.com/QwenLM/Qwen-VL
- Huggingface: http://huggingface.co/Qwen/Qwen-VL-Chat
- ModelScope: https://modelscope.cn/studios/qwen/Qwen-VL-Chat-Demo
- API: https://help.aliyun.com/zh/dashscope/developer-reference/tongyi-qianwen-vl-plus-api
- Discord: https://discord.gg/CV4E9rpNSD